Introduction
What is Murmurations?
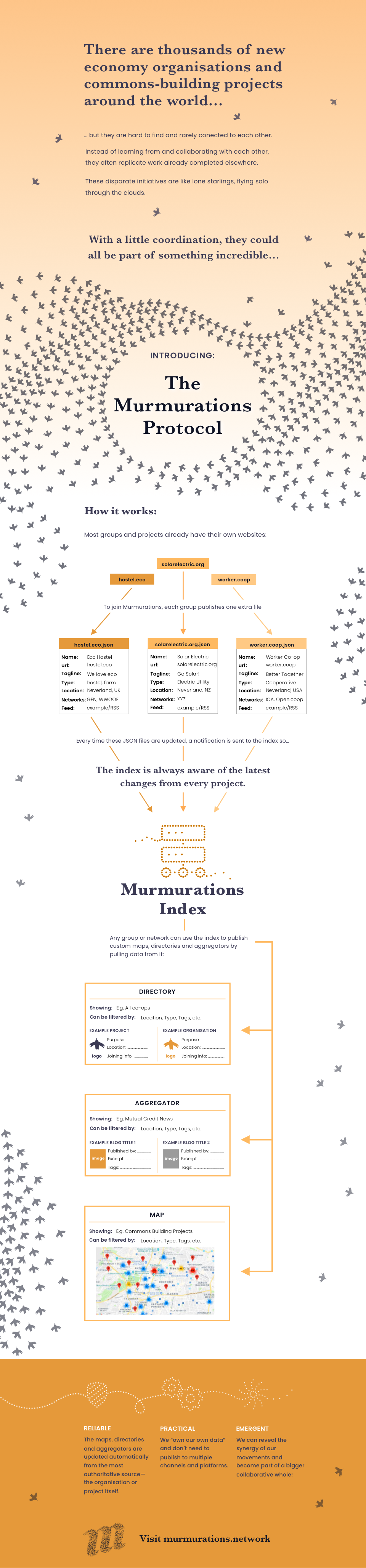
Murmurations is a distributed data sharing protocol for coordinating the storage, indexing and retrieval of data over a distributed network. The ultimate goal of Murmurations is to facilitate collaboration at scale by enabling interoperable data sharing across platforms and between networks, all while providing individuals and other data creators control over their data.
The distributed data sharing network is comprised of:
- Nodes and other data hosts that share data in the network
- Indexes that keep track of what data is available in the network and where it is located
- Aggregators that collect data from the network and display it in various ways
- Libraries of schemas that describe the data in the network
To enable these entities to work together, the Murmurations team has created:
- A protocol for defining and exchanging data based on existing standards such as JSON Schema and REST APIs
- Open source plug-ins and other code to make it as easy as possible to use, share and contribute data to the network
The initial use case for Murmurations is to facilitate decentralized mapping of purpose-driven solidarity economy organizations and projects, making them visible to the world and each other.
Further information about the distributed data sharing protocol can be found in the Murmurations White Paper.
How does it work?
The Murmurations protocol enables individuals and organizations (nodes) to create profiles about themselves in order to easily share information with aggregators, who create schemas to define the data they need to create maps, directories and content aggregators.
A library stores details of the schemas and the fields (data points such as name, geolocation, etc.) of which they are composed. A node obtains a schema from the library to determine the data needed to create a profile. You can try out the Murmurations Profile Generator to create a profile based on the schemas currently available in the library.
An index keeps track of nodes based on the schemas linked to their profiles. Whenever a node updates its profile it should tell the index. Aggregators regularly query the index for profile changes by nodes they want to track by referencing their schemas, enabling them to provide accurate and timely information in their maps, directories and content aggregators.
Why Murmurations?